There are two ways to deal with matrices in numpy. The standard numpy array in it 2D form can do all kinds of matrixy stuff, like dot products, transposes, inverses, or factorisations, though the syntax can be a little clumsy. For those who just can’t let go of matlab, there’s a matrix object which prettifies the syntax somewhat. For example, to do

import numpy as np #using arrays B = np.random.randn(2,2) # random array C = np.random.randn(2,2) A = np.dot(B.T, np.linalg.inv(C)) #using matrices B = np.mat(B) #cast as matrix C = np.mat(C) A = B.T*C.I
Despite the nicer syntax in the matrix version, I prefer to use arrays. This is in part because they play nicer with the rest of numpy, but mostly because they behave better in higher dimensions. This is really useful when you have to deal with lots of matrices, which seems to occur all the time in my work:
A = np.random.randn(100,2,2) # a hundred 2x2 arrays A2 = [np.mat(np.random.randn(2,2)) for i in range(100)] # a hundered 2x2 matrices
Transposing
Transposing the list of matrices is easy: just use the .T operator. This doesn’t work for the 100x2x2 array though, since it switches the axis in a way we don;t want. The solution is to manually specify which axes to switch.
A2T = [a.T for a in A2] # matrix version AT = np.transpose(A,(0,2,1)) #array version 1 #or AT = np.rollaxis(A,-2,-1)# array version 2
Multiplication
Suppose you have a series of matrices which you want to (right) multiply by another matrix. This is messy with the matrix object, where you need to do list comprehension, but nice as pie with the array object.
#matrix version A = [np.mat(np.random.randn(2,2)) for i in range(100)] B = np.mat(np.random.randn(2,2)) AB = [a*B for a in A] #array version A = np.random.randn(100,2,2) B = np.random.randn(2,2) AB = np.dot(A,B)
Left-multiplication is a little harder, but possible using a transpose trick:
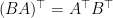
#matrix version BA = [Ba for a in A] #array version BA = np.transpose(np.dot(np.transpose(A,(0,2,1)),B.T),(0,2,1))
Okay, the syntax is getting ugly there, I’ll admit. Suppose now that you had two sets of matrices, and wanted the product of each element, as in

#matrix version A = [np.mat(np.random.randn(2,2)) for i in range(100)] B = [np.mat(np.random.randn(2,2)) for i in range(100)] AB = [a*b for a,b in zip(A,B)] #array version A = np.random.randn(100,2,2) B = np.random.randn(100,2,2) np.sum(np.transpose(A,(0,2,1)).reshape(100,2,2,1)*B.reshape(100,2,1,2),-3)
I’ll admit that the syntax of this is very weird. To see how it works, consider taking the (matrix) product of two arrays in a similar manner:
A = np.random.randn(2,2) B = np.random.randn(2,2) np.sum(A.T.reshape(2,2,1)*B.reshape(2,1,2),0)
The reshaping persuades numpy to broadcast the multiplication, which results in a 2x2x2 cube of numbers. Summing the numbers along the first dimension of the cube results in matrix multiplication. I have some scribbles which illustrate this, which I’ll post if anyone wants.
Speed
The main motivation for using arrays in this manner is speed. I find for loops in python to be rather slow (including within list comps), so I prefer to use numpy array methods whenever possible. The following runs a quick test, multiplying 1000 3×3 matrices together. It’s a little crude, but it shows the numpy.array method to be 10 times faster than the list comp of np.matrix.
import numpy as np import timeit #compare multiple matrix multiplication using list coms of matrices and deep arrays #1) the matrix method setup1 = """ import numpy as np A = [np.mat(np.random.randn(3,3)) for i in range(1000)] B = [np.mat(np.random.randn(3,3)) for i in range(1000)] """ test1 = """ AB = [a*b for a,b in zip(A,B)] """ timer1 = timeit.Timer(test1,setup1) print timer1.timeit(100) #2) the array method setup2 = """ import numpy as np A = np.random.randn(1000,3,3) B = np.random.randn(1000,3,3) """ test2 = """ AB = np.sum(np.transpose(A,(0,2,1)).reshape(1000,3,3,1)*B.reshape(1000,3,1,3),0) """ timer2 = timeit.Timer(test2,setup2) print timer2.timeit(100)
In the likely event that there’s a better way to do this, or I’ve screwed up some code somewhere, please leave me a comment 🙂

 ,
,  and
and  . These three are straightforward:
. These three are straightforward: , and so the expected value of
, and so the expected value of 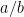 .
.  is
is  , and so the expected value of
, and so the expected value of  .
.  is a slightly more complex beast:
is a slightly more complex beast:  . Bizarrely, the rows share a covariance matrix. The expected value of
. Bizarrely, the rows share a covariance matrix. The expected value of  s.
s.  . The first thing to notice is that (where
. The first thing to notice is that (where  .
. 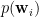 is Gaussian,
is Gaussian, 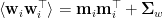 . Now we can write:
. Now we can write:
 , and the proportion of heterozygotes is
, and the proportion of heterozygotes is  .
. 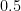 . Assuming random mating, show that amongst brown eyed parents with brown eyed children, the proportion of heterozygotes is
. Assuming random mating, show that amongst brown eyed parents with brown eyed children, the proportion of heterozygotes is  .
.
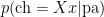 , prior
, prior  and a ‘marginal likelihood’ term, which we get by summing the above. So we’re going to get something like:
and a ‘marginal likelihood’ term, which we get by summing the above. So we’re going to get something like:
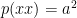

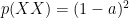
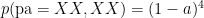
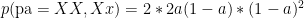
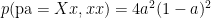
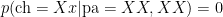
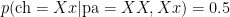

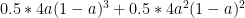

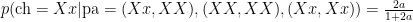
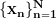 (this is your collected data), some latent paramenters
(this is your collected data), some latent paramenters 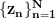 , with distribution
, with distribution  . There exists a noisy linear map
. There exists a noisy linear map 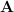 from the latent space to the observed variables:
from the latent space to the observed variables: 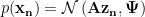 , where
, where 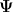 is a diagonal matrix.
is a diagonal matrix.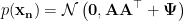 . It should now be clear that we are modeling the distribution of
. It should now be clear that we are modeling the distribution of 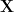 as a Gaussian distribution with limited degrees of freedom.
as a Gaussian distribution with limited degrees of freedom. , unnecessary components get ‘switched off’, and the corresponding column of A goes to zero. This is dead useful: you don’t need to know the dimension of the latent space beforehand: it just drops out of the model.
, unnecessary components get ‘switched off’, and the corresponding column of A goes to zero. This is dead useful: you don’t need to know the dimension of the latent space beforehand: it just drops out of the model. 